apache POIって名前可愛いと思いませんか?
可愛いですよね。
デモコード
import java.io.File; import java.io.FileOutputStream; import java.io.IOException; import org.apache.poi.EncryptedDocumentException; import org.apache.poi.ss.usermodel.Cell; import org.apache.poi.ss.usermodel.Row; import org.apache.poi.ss.usermodel.Sheet; import org.apache.poi.ss.usermodel.Workbook; import org.apache.poi.ss.usermodel.WorkbookFactory; import org.apache.poi.xssf.usermodel.XSSFWorkbook; public class ApachePOITest { private File file = new File("file.xls"); public static void main(String[] args) { new ApachePOITest(); } public ApachePOITest() { Workbook workbook = create(); write(workbook); Workbook workbook2 = read(); } private Workbook create() { Workbook workbook = new XSSFWorkbook(); Sheet sheet0 = workbook.createSheet(); Sheet sheet1 = workbook.createSheet("mySheet"); Row row0 = sheet0.createRow(0); Row row1 = sheet0.createRow(1); Cell cell0_0 = row0.createCell(0); Cell cell1_0 = row1.createCell(0); cell0_0.setCellValue("hoge"); cell1_0.setCellValue("huga"); row0.createCell(0); row1.getCell(0); return workbook; } private void write(Workbook workbook) { try (FileOutputStream stream = new FileOutputStream(file)){ workbook.write(stream); } catch (IOException e1) { e1.printStackTrace(); } } private Workbook read() { try { return WorkbookFactory.create(file); } catch (EncryptedDocumentException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } return null; } }
この、それなりに短いコードでエクセルデータの生成、データ編集、ファイル出力、ファイル読み込みが全てできています。
create //データ生成
private Workbook create() { Workbook workbook = new XSSFWorkbook(); Sheet sheet0 = workbook.createSheet(); Sheet sheet1 = workbook.createSheet("mySheet"); Row row0 = sheet0.createRow(0); Row row1 = sheet0.createRow(1); Cell cell0_0 = row0.createCell(0); Cell cell1_0 = row1.createCell(0); cell0_0.setCellValue("hoge"); cell1_0.setCellValue("huga"); row0.createCell(0); row1.getCell(0); return workbook; }
このメソッドではエクセルデータを生成し、シートを作成、セル2箇所にデータを書き込んで戻り値にしています。
Workbook workbook = new XSSFWorkbook();
ブック(エクセルファイル一つ分のデータ)を生成します。
XSSFはざっくりいうとエクセルのバージョンのことだそうで、XSSFは新しいやつです。
ざっくりですが、特別古いバージョンを使うこともあまりないと思うので、とりあえずXSSFを使っておけばいいのかと思います。
Workbook型は全てのブックに実装されるインタフェースです。
Sheet sheet0 = workbook.createSheet();
Sheet sheet1 = workbook.createSheet("mySheet");
シートを合わせて2つ生成しています。
引数なしの場合はデフォルトでシート名が付けられるようです。
引数に文字列を指定するとその名前が付けられます。
Row row0 = sheet0.createRow(0); Row row1 = sheet0.createRow(1);
今度はrowです。
rowはエクセル表の横一列を扱います。
引数に指定されている番号は行番号です。
Cell cell0_0 = row0.createCell(0); Cell cell1_0 = row1.createCell(0);
続いてセルです。
これが"A1"とか"E8"とかのセルになります。
引数に指定されているのは左からの列番号です。
0はA、1はBと順になっています。
cell0_0.setCellValue("hoge"); cell1_0.setCellValue("huga");
セルに対してsetCellValueメソッドを呼び出しています。
名前からして想像がつくかと思いますが、セルに対して文字列を書き込んでいます。
書き込みできる型は文字列、プリミティブ型、カレンダーなどがあります。
row0.createCell(0); row1.getCell(0);
ここで一つ注意をしておきます。
上の部分では既にcreateしているA1に対してもう一度createCellを呼び出しています。
この場合どうなるのでしょうか。
createCellを呼び出すことで、先ほどA1に書き込んだ"hoge"がなくなり、新しくA1セルが作り直されてしまうのです。
createRowでも同じです。1行目をもう一度createRowしてしまうと、せっかく作ったデータが1行丸ごと消えてしまいます。
既にcreateしてあるセルや行をもう一度手元に欲しい場合はgetCell,getRowを使うようにしましょう。
ただし、まだ生成していないセルや行をgetしようとした場合はnullが帰ってくるので、まずgetCellしてみて、nullが帰ってきたらcreateCellするというのが正しいやり方です。
write //ファイル書き込み
private void write(Workbook workbook) { try (FileOutputStream stream = new FileOutputStream(file)){ workbook.write(stream); } catch (IOException e1) { e1.printStackTrace(); } }
ファイルに書き込みます。
ほとんどが例外処理になっていますね。
やっているのはファイルストリームを作成してブックに渡しているだけです。
これだけでエクセルファイルが出力されているなんてとても楽ですね。
read //ファイル読み込み
private Workbook read() { try { return WorkbookFactory.create(file); } catch (EncryptedDocumentException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } return null; }
エクセルファイルを読み込みます。
読み込みに至ってはファイルストリームの生成すらしていません。
ただ読み込みたいFileを渡すだけです。
まとめ
もちろん手抜きプログラムなので例外処理はもう少しきちんとする方が良いのでしょうが、
エクセルを編集する手軽さは伝わったのではないかと思います。
他にもワードやパワーポイントを編集するライブラリもあるらしいので、必要があればそちらも使ってみたいものです。
今更ながらeclipseで外部ライブラリを使ったので覚書しとく
ライブラリを準備
今回はapache POIというexcelデータを操作するためのライブラリを例にします。
ダウンロードは今回の説明範囲外ということにします。
ライブラリをダウンロードし、解凍までされているところまで準備してください。

手順
プロジェクトを右クリックし、「新規」から「フォルダ」を選択します。
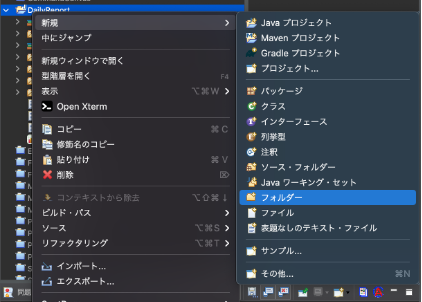
ウィンドウが立ち上がるので、新規作成するフォルダ名を設定します。
例では[「lib」という名前をつけました。
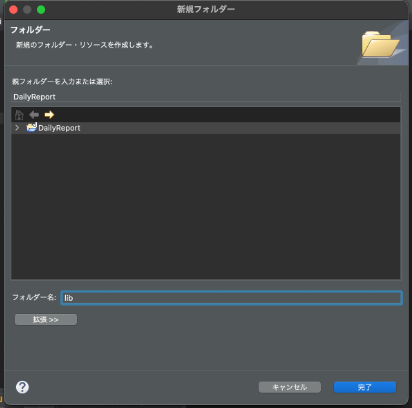
あらかじめ準備したライブラリをフォルダごとコピーします。
jarファイル1個しかないなどの場合はjarファイルだけでもokです。
プロジェクトファイルにライブラリがコピーできればフォルダ構造はなんでもいいのです。
先ほど作成したlibフォルダにライブラリを貼り付けます。
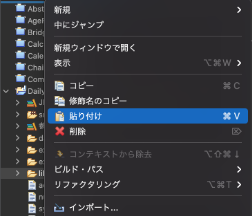
ライブラリのコピーが完了しました。
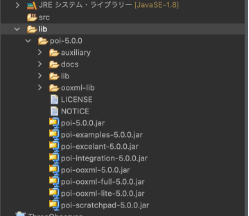
必要なjarファイルを全てビルドパスに追加します。
例ではどのjarが必要なのか調べるのが面倒なので全部追加しました。
追加されたライブラリは「参照ライブラリ」に表示されます。
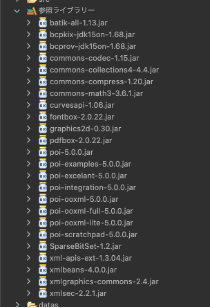
以上でライブラリの追加が完了です。
あとは今まで通りにコードを書きます。
コード保管も標準ライブラリと同様に動きます。
また完成したアプリケーションをjar圧縮する際も特別に設定する項目はありませんでした。
JavaでXMLデータ扱うの何だか難しそうだと思ってたけど実際やってみたら超簡単だった
- XMLとは
- Javaでの扱い方(DOM)
- デモコード
- import
- クラス
- create() //XMLデータの作成
- writeFile //ファイル保存
- readFile //ファイル読み込み
- print //コンソール出力
- 実行
XMLとは
こんなやつです。
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<parent>
<child>
<element>data1</element>
<element>data2</element>
</child>
</parent>よく見るとファイル構造と何となく似ています。
parentはフォルダ、childもフォルダ、elementはファイルでdata1,data2はファイルの中身です。
ファイル構造と違う点といえばelementが同じフォルダに重複していることですね。
Javaでの扱い方(DOM)
DOM(Document Object Model)とかSAXとかいくつか扱い方があるようですが、今回はDOMを使ったのでDOMで説明します。
デモコード
ひとまず全部載せます。
import java.io.File;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class XML {
private File file = new File("xml.txt");
public static void main(String[] args) {
new XML();
}
public XML() {
Document document = create();
writeFile(document);
Document document2 = readFile();
print(document2);
}
private Document create() {
DocumentBuilder builder = null;
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
builder = factory.newDocumentBuilder();
} catch (ParserConfigurationException e) {
e.printStackTrace();
return null;
}
Document document = builder.newDocument();
Element parent = document.createElement("parent");
document.appendChild(parent);
Element child1 = document.createElement("child");
parent.appendChild(child1);
Element element1 = document.createElement("element");
child1.appendChild(element1);
element1.appendChild(document.createTextNode("data1"));
Element element2 = document.createElement("element");
child1.appendChild(element2);
element2.appendChild(document.createTextNode("data2"));
return document;
}
private void writeFile(Document document) {
TransformerFactory factory = TransformerFactory.newInstance();
Transformer transformer = null;
try {
transformer = factory.newTransformer();
} catch (TransformerConfigurationException e) {
e.printStackTrace();
return;
}
transformer.setOutputProperty("indent","yes");
transformer.setOutputProperty("encoding","UTF-8");
try {
transformer.transform(new DOMSource(document),new StreamResult(file));
} catch (TransformerException e) {
e.printStackTrace();
return;
}
}
private Document readFile() {
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
if(!file.exists()) return null;
return builder.parse(file);
} catch (ParserConfigurationException | SAXException | IOException e) {
e.printStackTrace();
return null;
}
}
private void print(Document document) {
Element parent = document.getDocumentElement();
NodeList child_list = parent.getElementsByTagName("child");
Element child1 = (Element)child_list.item(0);
NodeList element_list = child1.getElementsByTagName("element");
for(int i=0;i<element_list.getLength();i++) {
System.out.println(
String.format(
"%s : %s",
element_list.item(i).getNodeName(),
element_list.item(i).getTextContent()));
}
}
}出力結果は冒頭で例に出したものがそうです。(若干見やすいように修正しています)
以降このコードを部分部分で見ていきます。
コードと出力結果を交互に見比べながら読み進めると理解しやすいかと思います。
import
import java.io.File; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerConfigurationException; import javax.xml.transform.TransformerException; import javax.xml.transform.TransformerFactory; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.NodeList; import org.xml.sax.SAXException;
Documentはjavax.swing.text.Document等いくつかありますが、org.w3c.dom.Documentを使用します。
クラス
public class XML {
private File file = new File("xml.txt");
public static void main(String[] args) {
new XML();
}
public XML() {
Document document = create();
writeFile(document);
Document document2 = readFile();
print(document2);
}
}fileフィールドは作成したxmlデータをテキストファイルで出力する出力先ファイル名です。
create() //XMLデータの作成
private Document create() {
DocumentBuilder builder = null;
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
builder = factory.newDocumentBuilder();
} catch (ParserConfigurationException e) {
e.printStackTrace();
return null;
}
Document document = builder.newDocument();
Element parent = document.createElement("parent");
document.appendChild(parent);
Element child1 = document.createElement("child");
parent.appendChild(child1);
Element element1 = document.createElement("element");
child1.appendChild(element1);
element1.appendChild(document.createTextNode("data1"));
Element element2 = document.createElement("element");
child1.appendChild(element2);
element2.appendChild(document.createTextNode("data2"));
return document;
}DocumentBuilderクラスはDocumentのオブジェクトを作成するのに必要です。
DocumentBuilderのインスタンス化に失敗した場合はその時点で例外によって処理が終了してしまいます。
builder.newDocument()で空のドキュメントを作成します。
このdocumentをファイル出力してみると、何もないXMLが出力されます。
ここから実際に中身(ファイルやフォルダのようなもの)を作っていきます。
Element parent = document.createElement("parent");
"parent"という名前のエレメントを作ります。この時点では中身のないエレメント、</parent>が作成されます。
document.appendChild(parent);
appendChildでエレメントをdocumentに組み込むことでやっとXMLにエレメントが一つ追加されます。
Element child1 = document.createElement("child");
次は子エレメントを作ります。
名前が違うだけでparentの時と同じことをしています。
parent.appendChild(child1);
どのオブジェクトからappendChildを呼び出しているかに注意してください。
parentを追加した先はdocumentですが、childを追加しているのはparentです。
documentに追加することで、そのエレメントはrootとなります。
parentのようなエレメントに追加することで、そのエレメントは子エレメントになります。
Element element1 = document.createElement("element"); child1.appendChild(element1); element1.appendChild(document.createTextNode("data1"));
これまたchild1と同じことをしていますが、3行目は初めて出てくる文です。
document.createTextNode()はエレメントの中身となるデータを作成します。
出力例でもelementの中にdata1というデータが一つだけ入っていることが見られます。
Element element2 = document.createElement("element"); child1.appendChild(element2); element2.appendChild(document.createTextNode("data2"));
同じことをしています。
以上で冒頭の例のXMLデータができました。
rootは一つしか追加できませんが、子エレメント、孫エレメントの数や深さはいくつでも増やすことができます。
作りたいXMLデータに応じて名前や数を変更してください。
writeFile //ファイル保存
private void writeFile(Document document) { TransformerFactory factory = TransformerFactory.newInstance(); Transformer transformer = null; try { transformer = factory.newTransformer(); } catch (TransformerConfigurationException e) { e.printStackTrace(); return; } transformer.setOutputProperty("indent","yes"); transformer.setOutputProperty("encoding","UTF-8"); try { transformer.transform(new DOMSource(document),new StreamResult(file)); } catch (TransformerException e) { e.printStackTrace(); return; } }
このメソッドでは作成したDocumentをファイル保存します。
TransformerFactory factory = TransformerFactory.newInstance(); Transformer transformer = null; try { transformer = factory.newTransformer(); } catch (TransformerConfigurationException e) { e.printStackTrace(); return; }
まずはtransformerを作ります。
ここでも例外が発生したらその時点で処理が終了します。
transformer.setOutputProperty("indent","yes"); transformer.setOutputProperty("encoding","UTF-8");
"indent"を"yes"にすると出力されるテキストファイルはエレメントごとに改行されます。
"no"にすると全て1行で書き込まれます。
"encoding"は出力するテキストの文字コードを指定します。
try { transformer.transform(new DOMSource(document),new StreamResult(file)); } catch (TransformerException e) { e.printStackTrace(); return; }
最後にファイルに出力します。
出力先ファイルは2行目で指定されてますね。
このメソッドを見てみると、Documentの内容に全く依存していないのがわかるかと思います。
つまり、保存先ファイル以外は丸コピーでも使えますね。
readFile //ファイル読み込み
private Document readFile() { try { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); if(!file.exists()) return null; return builder.parse(file); } catch (ParserConfigurationException | SAXException | IOException e) { e.printStackTrace(); return null; } }
このメソッドではファイルを読み込んで保存されているXMLを復元します。
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
この部分はcreateメソッドでも同じことをしていました。
Documentを作成する準備部分ですね。
if(!file.exists()) return null;
ファイルが存在するかを確認しています。
ファイルがないのに読み込もうとすると例外が発生します。
return builder.parse(file);
ファイルを読み込んでいます。
以上でXMLデータのファイルを読み込むことができました。
出力同様にデータの中身に依存しないので、丸コピーで読み込むことができます。
print //コンソール出力
private void print(Document document) { Element parent = document.getDocumentElement(); NodeList child_list = parent.getElementsByTagName("child"); Element child1 = (Element)child_list.item(0); NodeList element_list = child1.getElementsByTagName("element"); for(int i=0;i<element_list.getLength();i++) { System.out.println( String.format( "%s : %s", element_list.item(i).getNodeName(), element_list.item(i).getTextContent())); } }
XMLデータの解析をします。
Element parent = document.getDocumentElement();
documentからrootエレメントを取り出しています。
取り出されるのはcreateメソッドで作ったparentエレメントです。
NodeList child_list = parent.getElementsByTagName("child"); Element child1 = (Element)child_list.item(0);
続いてparentからgetElementByTagNameメソッドで"child"という名前のついたエレメントを取り出しています。
parentを取り出した時と型が違いますね。
NodeListはparentに含まれていて、名前が"child"のエレメントをまとめたリストのクラスです。
getDocumentElementで取り出されるのはrootエレメントです。
rootエレメントはXMLデータ内で一つしか存在しません。これはXMLデータのルールです。
一つしか存在しないのでリストにする必要はありませんね。
データ例をみるとelementエレメントが重複しています。
このようにrootでないエレメントは重複する可能性があるので、リストとして出力されているのです。
リストの中からエレメント一つを取り出すには、itemメソッドを使用します。
例ではコードの簡単化のために0番のエレメントが存在する前提として書いています。
NodeList element_list = child1.getElementsByTagName("element"); for(int i=0;i<element_list.getLength();i++) { System.out.println( String.format( "%s : %s", element_list.item(i).getNodeName(), element_list.item(i).getTextContent()));
同じように今度はchild1からエレメントのリストを読み出します。
forの条件でelement_list.getLenghtがありますが、リスト内にいくつエレメントが存在するかを数えます。
エレメント名を取り出すのはgetNodeNameメソッド、
データを取り出すのはgetTextContentメソッドです。
実行
実行してみましょう。
コンソール出力は次のようになります。
element : data1 element : data2
またテキストファイルが出力されているはずなので、そちらも確認してみましょう。
内容は次のようになっています。
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <parent> <child> <element>data1</element> <element>data2</element> </child> </parent>
インデントは有効にしているはずですが、インデントタブは付かないようです。
デザインパターンInterpreterについて勉強した
Interpreterパターンとは
インタプリタとは通訳のことです。
インタプリタといえばプログラム言語の一種、もしくはスクリプト言語として知っている人も多いのではないでしょうか。
Interpreterパターンはまさにそのスクリプト言語を作ろうというものです。
パターンの目的としてはアプリの動作を変更するのにコンパイルを必要としない、極限まで柔軟化したプログラムの一つとすることです。
作り方によればプログラミングの知識がないような人でもちょっと調べれば欲しい機能を実装できるようになります。
エクセルの関数なんかもそんな感じですね。
今回例として、入力した文字列を数式と読み取って計算してくれるスクリプトを作ってみましょう。
ただし、本格的に作るとそれこそ同人誌から技術書1冊分くらいの情報量になってしまうので、Interpreterの基本的な考え方がわかる程度として足し算、引き算のみを実装するようにします。
と言っても2つの数字を足し引きするだけでは流石に味気ないので、1+2-3+4のように足し算引き算であればいくらでも繋げられるようにはしたいと思います。
構文設計
まずはスクリプトの構文仕様を決めます。
BNF(バッカス・ナウア記法)
<integer> ::= "0"|"1"|"2"|"3"|"4"|"5"|"6"|"7"|"8"|"9"|<integer><integer> <operator> ::= "+"|"-" <number> ::= <integer>|<operator><number> <operation> ::= <operation><operator><operation>)|<number>
正規表現のようなものです。
「::=」は代入のような意味で考えればいいでしょう。
「<integer>は"0"~"9"のどれかです」のような意味になります。
一つずつみていきます。
<integer> ::= "0"|"1"|"2"|"3"|"4"|"5"|"6"|"7"|"8"|"9"|<integer><integer>
<integer>はJava言語でも整数クラスという意味ですね。
右辺には"0"~"9"が並んでおり、それぞれの間に|が挟まっています。これは0~9の文字どれかがあれば<integer>として扱うとなります。
最後に<integer><integer>があります。こちらは<integer>が2つ並んでいますが、これは<integer>が2つ並んでいるものも1つの<integer>として扱うという意味になります。<integer>が2つで1つの<integer>になるので、それらを合わせた(全部で4つ,またそれ以上並んだ)<integer>も1つとして扱うという意味にもなります。再起的な表現ですね。
ここでは説明のためあえて書きましたが、数値の定義まで書くのはめんどくさいということで「数値」や「文字列」のルールは書かない場合もあるようです。
<operator> ::= "+"|"-"
今度は<operator>です。
<integer>と比べるとシンプルですね。"+"もしくは"-"のどちらかという意味です。
<number> ::= <integer>|<operator><number>
<number>は数値という意味です。
<integer>とはどう違うのでしょうか。
定義をよく読んでみると<integer>には数字の前に"-"がついた0より小さい数については説明されていません。ただの数列のみです。
<number>は数列の前にマイナスがついた0より小さい数字、もしくはマイナスのつかない0以上の数字について説明されています。
<integer>の方にマイナスのついた数列を定義するのは難しいです。<integer>の連続で再帰しているので、例えば12-34という文字列も<integer>として説明できてしまうためです。
<operation> ::= <operation><operator><operation>)|<number>
最後に<operation>です。数式を表しています。
まず<operation>は<number>単体でもそれとして扱うことができます。つまり、「1」も「1234」も<operation>です。
<opeator>は「+」もしくは「-」でしたね。ということは<operation><operator><operation>の部分は「1+1234」にマッチします。
よくみるとここでも再帰がありますね。ということは「1+1234」<operator><operation>と考えられるので、「1+1234」の後にさらに「-56」を付け足すこともできます。このように無限に式を伸ばすことが可能です。
コード例
それではコードを見ていきましょう。
Lexerクラス
public class Lexer { private String integer_regex = "\\d+"; private String operator_regex = "\\+|-"; public Token[] toTokens(String code) throws ParserException{ if(code==null) return new Token[0]; code = code.trim(); Pattern pattern = Pattern.compile(String.format("(\s*%s)|(\s*%s)", integer_regex,operator_regex)); Matcher matcher = pattern.matcher(code); ArrayList<Token> tokens = new ArrayList<Token>(); int index = 0; while(index<code.length()) { if(!matcher.find(index)) { throw new ParserException("字句解析に失敗しました"); } tokens.add(createToken(matcher)); index = matcher.end(); } return tokens.toArray(new Token[0]); } public Token createToken(Matcher matcher) { Token token = null; if(matcher.group(1)!=null) { token = new Token(TokenType.NUMBER,matcher.group(1).trim()); } if(matcher.group(2)!=null) { token = new Token(TokenType.OPERATOR,matcher.group(2).trim()); } //System.out.println(token); return token; } }
字句解析をするクラスです。
例えば「1+234-56」をプログラムが解釈するとき、「1」「+」「234」「ー」「56」に分ける必要があります。これら単体を字句と呼び、文字列を字句に分解、解析することを字句解析と言います。
integer_regexとoperator_regexという2つのフィールドがあります。
中身は正規表現です。
integer_regexは<integer>に、operator_regexは<operator>にそれぞれ対応しているのがわかるでしょうか。
toTokensメソッドは字句解析をするときに最初に呼び出されるメソッドです。
throwsがついていますね。構文的におかしな文字列が渡された時は例外を出して解析を中止するようにします。
pattern変数は各字句のパターンを設定しています。
tokens変数は解析できた軸を補完するためのリストです。
index変数は、現在どこまで解析ができたかを保持するためのものです。
whileループです。
indexがコードの文字数よりも多くなったら全コードを解析できたということでループを終了します。
if文の!matcher.findはマッチする文字列がなかった場合の処理です。
まだ解析できていないコードが残っているのにマッチしない場合、これは本来コードに含まれるべきではない文字が含まれていることが考えられるため、例外を出します。
その後createTokenメソッドにマッチ結果を丸投げします。
ここまでくればコードの先頭の字句は正常に読み取れているはずです。
createtokenメソッドを見てみます。
matcher.group(1)!=nullに注目します。
group(1)とは正規表現でマッチした部分の1つ目を読み出すメソッドです。
パターンを見直してみましょう。
String.format("(\s*%s)|(\s*%s)", integer_regex,operator_regex)
パターンは"(\s*%s)|(\s*%s)",となっています。
group(0)だと全体にマッチします。つまりinterger_regexにマッチした場合でもoperator_regexがマッチした場合でも何かしらの文字列が返されます。
group(1)では1つ目の括弧の中身が返されます。つまりこのパターンの場合はinteger_regexにマッチした場合のみ文字列が返され、operator_regexにマッチした場合はnullが返ります。
group(2)だとその逆で、opearator_regexにマッチした場合に文字列が返り、integer_regexにマッチした場合はnullが変えることになります。
それを踏まえてif文をみてみるとif(matcher.group(1)!=null) {はinteger_regexがnullではない、つまりinteger_regexにマッチしているということになります。
マッチするものが見つかったらTokenクラスのインスタンスを作って返します。
TokenType
public enum TokenType { OPERATOR, NUMBER, }
字句の種類です。
operatorつまり演算子とnumberつまり数字の2種類です。
Tokenクラス
public class Token { private TokenType type ; private String name; public Token(TokenType type,String name) { this.type = type; this.name = name; } public TokenType getType() { return type; } public String getName() { return name; } @Override public String toString() { return type + "\t" + name; } }
字句1つを表すクラスです。
自身のタイプと名前("+"や"-"、"123"など)を保持するだけのものです。
ParserExceptionクラス
public class ParserException extends Exception { public ParserException(String message) { super(message); } }
構文解析できなかった場合の例外クラスです。
ここまでできたら一度実行してみましょう。
createTokenメソッドの最後にSystem.out.println(token);の一文を追加すると解析状況がわかります。
今度は構文解析と実行のコードを書いていきます。
Nodeクラス
public abstract class Node { public abstract int execute(); }
Nodeは数値、計算式などを表す抽象クラスです。
実際の処理はサブクラスに実装します。
NumberNodeクラス
public class NumberNode extends Node { private int number ; public NumberNode(int number) { this.number = number; } @Override public int execute() { return number; } }
<number>を担当するクラスです。
numberフィールドで数値を保持します。
executeメソッドは計算の実行をしますが、このクラスはただの数値なので処理もただ保持している数値を返すだけになっています。
OperationNodeクラス
public class OperationNode extends Node { private Node left ; private Token operator ; private Node right ; public OperationNode(Node left,Token operator,Node right) { this.left = left; this.operator = operator; this.right = right; } @Override public int execute() { if(operator.getName().equals("+")) { return left.execute()+right.execute(); }else { return left.execute()-right.execute(); } } }
<opearation>を担当し、計算式を表すクラスです。
フィールドを見てみると3つあります。
leftは計算式の左を担当するNodeです。これが<number>なのか<operation>なのかはこの時点ではわかりません。コンストラクタに渡されたNodeによって変わります。
operatorは演算子で、「+」もしくは「ー」になります。
rightは計算式の右を担当するNodeです。leftと同様に何が入るかはわかりません。
executeメソッドはoperatorが「+」か「ー」かによって処理が足し算か引き算に変わります。
NumberNodeよりは難しいですがまだなんてことはありません。
Parserクラス
public class Parser { private int index ; private Token[] tokens ; public Node toNode(Token[] tokens) throws ParserException{ index = 0; this.tokens = tokens; return toOperationNode(); } public Node toOperationNode() throws ParserException{ Token token = currentToken(); if(token==null) return null; Node node = toNumberNode(); while((token=currentToken())!=null) { if(token.getType()!=TokenType.OPERATOR) { throw new ParserException("計算式は+/-のみ有効 : "+token); } nextToken(); node = new OperationNode(node,token,toNumberNode()); } return node; } public Node toNumberNode() throws ParserException{ int i = 1; Token token ; while((token=currentToken())!=null) { if(token.getType()==TokenType.OPERATOR) { if(token.getName().equals("-")) { i *= -1; } nextToken(); }else { break; } } if(token==null) throw new ParserException("数値を入力してください"); nextToken(); return new NumberNode(Integer.parseInt(token.getName())*i); } public boolean hasCurrent() { return index<tokens.length; } public Token currentToken() { if(!hasCurrent()) { return null; } return tokens[index]; } public Token nextToken() { index++; return currentToken(); } }
構文解析をするクラスです。
indexフィールドはトークン列のどこまで解析が済んでいるかを保持します。
tokensフィールドは解析対象のトークン列を保持します。
コンストラクタでは渡された値をフィールドに保持し、toOperationNodeメソッドを呼んで解析を開始します。
toOperationNodeメソッドはOperationNodeを生成するメソッドです。
currentTokenは現在参照しているトークンを返すメソッドで、この戻り値がnullであるということはそもそもコードがないということです。
まずは式の左の数値を解析します。
whileでは続いて演算子がある場合の解析をしています。
演算子を保持し、演算子があるということはさらに続いて数値があるはずなので、あると決めてtoNumberNodeを呼びます。もし数値がなければtoNumberNodeから例外が返ってきます。
所々で無駄にnextTokenを呼び出していますね。現在どのトークンを参照しているか、次に呼び出すメソッドはどこが参照されていることを前提として設計されているかを意識しないと、トークンの読み飛ばしや2重に読んでしまうなどが起こってしまうので、注意が必要です。
toNumberNodeメソッドを見てみましょう。
whileループがありますが、これは「+」「ー」が並んでいる間はループし続けます。
「ー」が出てくるたびに数値の符号を反転するためです。
符号が出てこなければループを脱します。
脱しても数字が出てこなければ例外です。
hasCurrentメソッドは現在参照しているトークンが存在するかを返します。
存在しない、falseが変えるということはトークン列の最後に達したということになります。
currentTokenメソッドは現在参照しているトークンを返します。
存在しなければnullを返します。
nextTokenメソッドは参照するトークンを次へ進めて、次のトークンを返します。
存在しなければnullを返します。
public class Main { public Main() { Scanner scanner = new Scanner(System.in); while(true) { try { System.out.println("計算式を入力してください"); String code = scanner.nextLine(); if(code.equals("exit")) break; Lexer lexer = new Lexer(); Token[] tokens = lexer.toTokens(code); Parser parser = new Parser(); Node node = parser.toNode(tokens); if(node==null) continue; int response = node.execute(); System.out.println(">>"+response); } catch (ParserException e) { System.out.println(e.getMessage()); } System.out.println(); } scanner.close(); } public static void main(String[] args) { new Main(); } }
今回もScannerでコンソール入力をするようにしました。
ループ条件は常にtrueです。
式を入力して、「exit」だったらループを抜けて終了します。
入力された式をLexerに渡し、字句解析されたトークン列を取得します。
さらにトークン列をParserに渡し、構文解析されたノードを取得します。
ここでもし式が入力されていなければnullが返ってきているので、nullチェックをしておきます。
ノードのexecuteを呼び出すことで式の計算を開始します。
実行
計算式を入力してください 1+1 >>2 計算式を入力してください 100+1 >>101 計算式を入力してください 10-5 >>5 計算式を入力してください 5--1 >>6 計算式を入力してください 5-----2 >>3
特徴
ユーザーがコードを書くことで処理が変化できるような、非常に柔軟なアプリを作ることができます。
本格的なスクリプト言語を作ることもあれば、アプリの補助機能として簡単なものを実装することもあります。
まとめ
今回は足し算と引き算しかしないスクリプトを作りました。
ちょっとごちゃっとした感じになりましたが、これは簡単な方です。
というのも、実際の計算では算数レベルでも掛け算や割り算が出てきます。掛け算割り算は足し算引き算に比べて優先順位が高いものです。さらに括弧のついた式を考えるとさらに複雑になります。
この優先順位を避けるために足し算引き算のみにしましたが、掛け算割り算を実装した途端に難易度がぐんと上がったような記憶があります。
エディタ系や自動化系のアプリを作るときには結構欲しくなる機能なので、覚えておいて損はないと思います。
デザインパターンBridgeについて勉強した
bridgeパターンとは
bridge(ブリッジ)は橋のことです。
機能と実装の橋渡しをします。
クラスの継承をするのには主に2つの理由があります。1つはメソッドを追加すること、もう一つはメソッドを書き換える(オーバライド)ことです。
メソッドを追加することによってできるクラス階層(クラスの親子関係)を機能の階層と呼びます。
オーバライドすることによってできるクラス階層を実装の階層と呼びます。
この機能の階層と実装の階層をごちゃごちゃにクラス階層を作ってしまうとどんどんクラス関係が複雑になってしまいます。
そこで、機能と実装を別々に作ることで全体の見通しや今後の拡張性を上げることができるようになります。
コード例
GreetingImpleインタフェース
public interface GreetingImple { String type(); String morning(); String noon(); String night(); }
これは「実装の階層」になるクラスが実装するインタフェースです。
実装されていないので一見「機能の階層」と勘違いしそうですが、このインタフェースを実装したクラスのことを「実装の階層」とします。
実装の階層はこのインタフェースの直下のクラスだけと考えてください。
つまり、クラス1でtypeメソッドを実装した後、クラス1を継承したクラス2でtypeメソッドをオーバライドするようなことはしてはいけません。
typeメソッドの実装を変えたければ新たにGreetingImpleインタフェースを実装した別のクラスとして作るべきです。
Greetingクラス
public class Greeting { private GreetingImple imple ; public Greeting(GreetingImple imple) { this.imple = imple; } public String type() { return imple.type(); } public String morning() { return imple.morning(); } public String noon() { return imple.noon(); } public String night() { return imple.night(); } }
「機能の階層」となるクラスです。
コンストラクタでは先ほど説明したGreetingImpleを受け取り、そのほかのメソッドでは全てGreetingImpleに処理を委譲しています。
全てのメソッドで処理を委譲している。つまり実装は全て「実装の階層」であるGreetingImpleに任せているのです。
ぼんやりと「機能の階層」と「実装の階層」の意味が見えてきましたか?
GreetingCatalogクラス
public class GreetingCatalog extends Greeting { public GreetingCatalog(GreetingImple imple) { super(imple); } public void greetingCatalog() { System.out.println(String.format("%sの挨拶は", type())); System.out.println(String.format("朝は「%s」,", morning())); System.out.println(String.format("昼は「%s」,", noon())); System.out.println(String.format("夜は「%s」です", night())); } }
「機能の階層」側のサブクラスです。
新たにgreetingCatalogメソッドという「機能」を追加しました。
ぱっと見「実装の階層」に対する委譲が見当たらないので、このメソッドは「実装」側ではないかと思うかもしれませんが、ここで呼び出されているtype,morning,noon,nightメソッドは全てGreetingImpleへの移譲をしています。
しかし実際このメソッドが実装よりであることも間違いないのでどちらが正解とも言い切れません。
実装
Humanクラス
public class Human implements GreetingImple { private String morning ; private String noon; private String night; public Human(String morning,String noon,String night) { this.morning = morning; this.noon = noon; this.night = night; } @Override public String type() { return "人間"; } @Override public String morning() { return morning; } @Override public String noon() { return noon; } @Override public String night() { return night; } }
人間の挨拶を返すクラスです。
「実装の階層」ですね。
メソッドは全てインタフェースから実装したものです。
この例では非常に簡単な内容になっていますが実装の階層なのでいくらでも複雑な内容にできます。(読みづらいコードを書いてもいいという意味ではありません)
Gorillaクラス
public class Gorilla implements GreetingImple { public Gorilla(String morning,String noon,String night) { } @Override public String type() { return "ゴリラ"; } @Override public String morning() { return "ウホウホ"; } @Override public String noon() { return "ウホウホ"; } @Override public String night() { return "ウホウホ"; } }
こちらも「実装の階層」です。
コンストラクタに引数はありますが、全く使っていませんね。
typeメソッド以外では全てウホウホ言っているだけです。
public class Main { public Main() { GreetingCatalog human_catalog = new GreetingCatalog(new Human("おはよう","こんにちは","こんばんは")); human_catalog.greetingCatalog(); System.out.println("================"); GreetingCatalog gorilla_catalog = new GreetingCatalog(new Gorilla("おはよう","こんにちは","こんばんは")); gorilla_catalog.greetingCatalog(); } public static void main(String[] args) { new Main(); } }
それぞれのインスタンスを生成し、引数には朝昼夜の挨拶を渡しています。
greetingCatalogメソッドを呼ぶことで、人とゴリラそれぞれの挨拶について説明を始めます。
特徴
「機能の階層」を変更することなく人間とゴリラの2種類の実装を実現することができました。
今後新たに別の機能を追加するときにも、機能の階層を増やすだけで済みます。
機能と実装を分けなかった場合を想像してみましょう。
+Greeting
+HumanGreeting
+HumanGreetingCatalog
+GorillaGreeting
+GorillaGreetingCatalogここにアメリカ人を追加した場合、追加したいのはアメリカ人1つなのに2つのクラスを追加しないと全体の統一ができなくなります。
+Greeting
+HumanGreeting
+HumanGreetingCatalog
+GorillaGreeting
+GorillaGreetingCatalog
+AmericanGreeting
+AmericanGreetingCatalogさらに朝昼夜の挨拶をランダムに出力するメソッドを追加してみましょう。(実用性があるかは目を瞑ってください)
+Greeting
+HumanGreeting
+HumanGreetingCatalog
+HumanGreetingRandom
+GorillaGreeting
+GorillaGreetingCatalog
+GorillaGreetingRandom
+AmericanGreeting
+AmericanGreetingCatalog
+AmericanGreetingRandomこうなるとどれがどのクラスか分かりにくいですし、HumanGreetingRandomクラスとAmericanGreetingRandomクラスは全く別クラスなので、同じメソッドを持っているのにコードの共通化ができないなどが発生してきます。
中身は全く同じrandom(HumanGreetingRandom random)メソッドとrandom(GorillaGreetingRandom random)メソッド、random(AmericanGreetingRandom random)メソッドを作らなくてはいけないなんて面倒ですし、あとで修正するときにも間違いや変更もれがありそうですよね。
ではこれをブリッジパターンに書き換えてみます。
+Greeting
+GreetingCatalog
+GreetingRandom
+GreetingImple
+Human
+Gorilla
+Americanずいぶんシンプルになりましたね。
これならアメリカ人だけの処理をしたい時もrandom(GreetingRandom random)メソッドを作るときも困りません。
まとめ
今回の例では実装の階層もかなり単純な内容になっています。
実用的に考えると、例えばダイアログを表示する実装、ファイル出力をする実装、メールを送る実装など考えられます。
具体的な部分とそれの使い方でクラスを分けるという考え方はほとんどのデザインパターンに言えることです。
デザインパターンbuilderについて勉強した
builderパターンとは
builderは何かを作る、組み立てるという意味の英語です。
ブログ記事を書くときと、新聞記事を書くときでは使うツールも作業も違います。
しかしブログ記者にタイトルと本文を渡せばブログ記事が出来上がりますし、新聞記者にタイトルと本文を渡せば新聞記事が出来上がります。
依頼者は相手がどちらであっても、「これがタイトルです」「これが本文です」と同じように情報を渡すだけで完成した記事を得ることができるのです。
具体的な記事の作り方はそれぞれの記者が知っています。
依頼者は誰に依頼する時でも同じように情報を渡せば良いのです。
唯一気にするべきなのは必要な記事が欲しいときは誰に依頼すればいいのか(ブログなのか新聞なのか)だけです。
あるいは元請け人がいる場合はそれすら気にする必要もないのかもしれません。
コード例
ブログと新聞の書き分けはできませんので、コンソールに出力する記者と、ダイアログに出力する記者に仕事を依頼することにします。
Reporterクラス
public abstract class Reporter { public abstract void setTitle(String title) ; public abstract void setBody(String text) ; public abstract void show(); }
記者の抽象クラスです。
この人が「ブログ記者」なのか「新聞記者」なのかはたまたそれ以外なのかはまだわかりません。
記事を書くにはtitleとbody(本文)が必要です。
setTitleメソッドは依頼者からタイトルを教えてもらうためのメソッド、
setBodyメソッドは依頼者から本文を教えてもらうためのメソッドです。
showメソッドは完成した記事を見せてくれるためのメソッドです。
全て抽象メソッドとなっています。
実装するのはサブクラスの記者達です。
実装
ConsoleReporterクラス
public class ConsoleReporter extends Reporter { private StringBuffer buff = new StringBuffer(); @Override public void setTitle(String title) { buff.append("<< " + title + " >>"); buff.append("\n"); } @Override public void setBody(String text) { buff.append(text); buff.append("\n"); } @Override public void show() { System.out.println("================"); System.out.println(buff); System.out.println("================"); } }
コンソール記者です。
buffフィールドは記事内容を保管するためのものです。
setTitleメソッドは記事にタイトル文を加えます。
setBodyメソッドは記事に本文を加えます。
showメソッドはコンソールに記事を表示します。
public class DialogReporter extends Reporter { private String title ; private String text ; @Override public void setTitle(String title) { this.title = title; } @Override public void setBody(String text) { this.text = text; } @Override public void show() { JOptionPane.showMessageDialog(null,text,title,JOptionPane.PLAIN_MESSAGE); } }
ダイアログ記者です。
title,bodyに関しては説明は不要でしょうか。
showメソッドはダイアログを表示します。
public class Main { public static final String CONSOLE = "console"; public static final String DIALOG = "dialog"; public Main() { Scanner scanner = new Scanner(System.in); String text = ""; while(!CONSOLE.equals(text) && !DIALOG.equals(text)) { System.out.print(String.format("入力してください(%s/%s):",CONSOLE,DIALOG)); text = scanner.nextLine(); } scanner.close(); Reporter reporter ; if(CONSOLE.equals(text)) { reporter = new ConsoleReporter(); }else { reporter = new DialogReporter(); } reporter.setTitle("Builderパターンとは"); reporter.setBody("builderパターンはデザインパターンの一つです"); reporter.show(); } public static void main(String[] args) { new Main(); } }
依頼者です。
コンソールから入力した内容によって、コンソール記者かダイアログ記者かどちらに依頼するかを選択します。
reporter.setTitleではタイトルを、setBodyでは本文を渡して「こんな記事を書いてください」とお願いをしています。
最後にshowメソッドでできた記事を見せてもらっています。
特徴
AbstractFactoryになんとなく似ていますが、AbstractFactoryは使っているクラスが具体的に何なのかを意識しなくていいパターンです。
対してBuilderパターンは「書きたい記事の内容」と「記事を書くための専門知識」を切り離して考えられ、依頼者側は必要なものを並べるだけで欲しいものが作れるようになります。
まとめ
例えば今書いているこの記事でも、私はWebページの知識はなくてもタイトルと本文、それにタグだけ作れば作りたい記事が書けています。
URLやHTML/CSSのような専門知識はほぼ皆無なのにです。
このように、簡単な情報を組み立てるだけで本格的なものが作れるようにするのがこのパータンです。
デザインパターンFlyweightについて勉強した
flyweightパターンとは
ボクシングなどのフライ級を意味します。
プログラミングでは軽量化と言ったような意味になります。
クラスを扱うにはインスタンスを生成します。
プログラムにもよりますが、オブジェクトが千や万も作られることもあるかもしれません。
また、オブジェクト数はそれほど多くはないけれど、一つ一つのオブジェクトのメモリ量が多いこともあります。
オブジェクトの数が多いほどpcのメモリは圧迫され、動作が遅くなっていきます。
メモリを節約するにはどうすればいいでしょうか。
その方法の一つに、同じ内容のオブジェクトは作らずに使い回すことが考えられます。
例えば画面上に同じ写真を10個並べて表示するプログラムを作ったとしましょう。
同じ画像ファイルを10回読み込むのでは明らかに無駄です。
読み込みは1回だけにして、残り9個は最初に読み込んだオブジェクトの参照を渡してやればいいのです。
コード例
ここではランダムに文字を選択して並べ、特定の文字列が揃ったらあたりになるプログラムを作ってみます。
CharItemクラス
public class CharItem { private char item ; public CharItem(char item) { this.item = item; } public char getItem() { return item; } @Override public String toString() { return ">>> " + item + " <<<"; } }
文字一つを表すクラスです。
既にcharクラスがあるので本当は不要ですが、説明のために作りました。
このクラスが何か重いデータを持っている(gif画像データなど)と考えてください。
ItemFactoryクラス
public class ItemFactory { private static ItemFactory factory = new ItemFactory(); private HashMap<Character,CharItem> items = new HashMap<Character,CharItem>(); private ItemFactory() { } public static ItemFactory getInstance() { return factory; } public CharItem createItem(char c) { CharItem item = items.get(c); if(item==null) { item = new CharItem(c); items.put(c, item); } return item; } }
CharItemクラスを作成するためのクラスです。
シングルトンパターンになっています。
itemsフィールドは既に作成済みのCharItemを保持しておくためのものです。
createItemメソッドは、渡されたcharを元にCharItemを返します。
既に作成済みであればitemsフィールドに保持されたものを返し、未作成であれば新たにオブジェクトを生成しています。
このメソッドがflyweightパターンの本体です。
使いまわせるものがあればそれを使い、なければ新しく作ることで無駄なメモリの使用を抑えようとしています。
実装
ItemStackクラス
public class ItemStack { private CharItem[] items = new CharItem[0]; private char[] elements = new char[] { 'O','C','H','I','N', }; private String[] lucky_text = new String[] { }; public boolean randomItems(int size) { Random random = new Random(); ItemFactory factory = ItemFactory.getInstance(); items = new CharItem[size]; try { for(int i=0;i<size;i++) { items[i] = factory.createItem(elements[random.nextInt(elements.length)]); System.out.println(items[i]); Thread.sleep(500); } }catch(InterruptedException e) { e.printStackTrace(); } lucky: for(String text : lucky_text) { if(text.length()!=size) continue; for(int i=0;i<size;i++) { if(items[i].getItem()!=text.charAt(i)) continue lucky; } System.out.println("おめでとうございます!!!!"); return true; } System.out.println("残念..."); return false; } public boolean randomItems() { return randomItems(9); } public void auto() { while(!randomItems()); } }
特定のcharからランダムにいくつか選択し、特定の文字列になったらあたりになるゲームです。
itemsフィールドは、最後に選択されたCharItemの羅列を保持します。
elementsフィールドは選択できるcharです。
lucky_textフィールドは当たりの文字列です。elementsフィールドに含まれる文字で好きな文字列を入力してください。
randomItemsメソッドは、渡された数のCharItemの列を作り、それがあたりかどうかを判定しています。
forの中でCharItemを生成しています。factory.createItem(elements[random.nextInt(elements.length)]);
これで、既に作られているものと同じオブジェクトは新たに生成されず、以前に作ったものを使いまわすようになります。
randomItemsメソッドはオーバロードされています。
引数なしの場合はデフォルトで9文字の文字列をランダム生成します。
autoメソッドは、当たりが出るまで回し続けるメソッドです。
実行
public class Main { public Main() { ItemStack stack = new ItemStack(); //stack.randomItems(); stack.auto(); } public static void main(String[] args) { new Main(); } }
stack.autoメソッドで当たりが出るまで回し続けます。
randomItemsに変えると、1回の実行ごとに1回だけになります。